Chapter 01: Log-Linear Model¶
1. Introduction¶
Solomon and Wynne conducted an experiment on Dogs in 1953 . They wanted to understand, whether Dogs can learn from mistakes, so to speak. Specifically, they were interested in avoidance-learning. That is, when Dogs are given trauma-inducing shocks, will they learn to avoid shocks in future?
We can state the objectives of the expeirment, according to our understanding, in more general terms as follows:
Can the Dogs learn?
Can they retain & recollect what they learnt?
The experimental setup, to drive the objectives, holds a dog in a closed compartment with steel flooring, open on one side with a small barrier for dog to jump over to the other side. A high-voltage electric shock is discharged into the steel floor intermittently to stimulate the dog. The dog is then left with an option to either get the shock for that trial or jump over the barrier to the other side & save himself. Several dogs were recruited in the experiment.
The following picture (source) is an illustration of the setup.
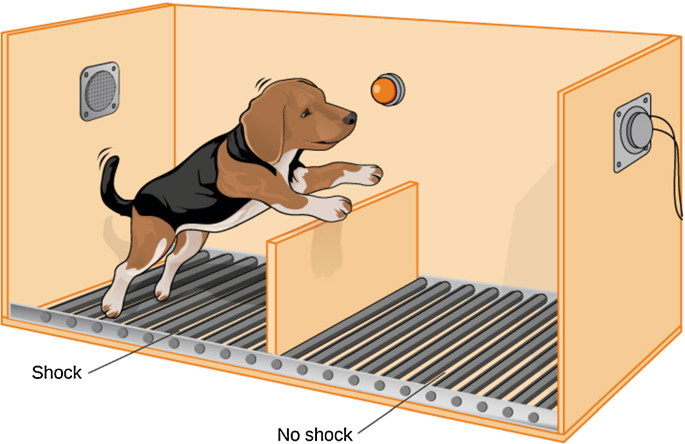
More details of the experiment can be found here.
{kind=link}
In this chapter, we will analyze the experimental data using Bayesian Analysis, and the inference will be carried out in Pyro. The organization of the notebook is inspired from Bayesian Workflow by Prof. Andrew Gelman et al. Another piece of work in that direction is from Betancourt et al here. However, the current analysis is a WIP and far from perfect.
An almost always first step in Bayesian Analysis is to elicit a plausible generative model, that would have likely generated the observed data. In this case, consider the model suggested/implemented in WinBUGs Vol1.
We want to model the relationship between avoidance-in-future and past-traumatic-experiences. The following log-linear model is a starting point:
\(\pi_j = A^{xj} B^{j-xj} \)
where :
\(\pi_j\) is the probability of a dog getting shocked at trial \(j\).
\(x_j\) is number of successful avoidances of shock prior to trial \(j\).
\(j-x_j\) is number of shocks experienced prior to trial \(j\).
A & B, both are unknown and treated as random variables.
However, the model is only partially complete. In a Bayesian setting, we need to elicit our prior beliefs about the unknowns. Consequently, we need to give priors to \(A\) and \(B\), which we do shortly. Before that, we need some boiler plate code, mostly imports. Note that, all the code (functions) are glued in the base class. If one is interested, they can always browse the code repo to get better understanding.
import torch
import pyro
import pandas as pd
import itertools
from collections import defaultdict
import matplotlib.pyplot as plt
import pyro.distributions as dist
import seaborn as sns
import plotly
import plotly.express as px
import plotly.figure_factory as ff
from chapter01 import base
import numpy as np
pyro.set_rng_seed(1)
plt.style.use('default')
%matplotlib inline
%load_ext autoreload
Data¶
The data contains experiments over 30 dogs and each dog is subjected to 25 trials.
The plot that follows highlights Dogs data in dictionary format, averaged over dog population for each trial, i.e., \(y_j = \frac{1}{30}\sum{y_{ij}}\) where \(y_{ij}\) is the i-th Dog’s response at the j-th trial.
dogs_data = base.load_data()
base.plot_original_y(1-np.mean(dogs_data["Y"], axis=0), ylabel='Probability of shock at trial j')
Its apparent from experimental data that more than half the dog population learns to avoid shocks in trials as few as 5, and also that the learning doesn’t significantly rise with increased number of trials.
Preprocessing¶
Next, we need to transform raw data to obtain:
x_avoidance: number of shock avoidances before current trial.x_shocked: number of shocks before current trial.y: status ‘shocked (y=1) or avoided(y=0)’ at current trial.
Here pystan format data (python dictionary) is passed to the function above, in order to preprocess it to the tensor format required for pyro sampling.
x_avoidance, x_shocked, y = base.transform_data(**dogs_data)
print("x_avoidance: %s, x_shocked: %s, y: %s"%(x_avoidance.shape, x_shocked.shape, y.shape))
print("\nSample x_avoidance: %s \n\nSample x_shocked: %s"%(x_avoidance[1], x_shocked[1]))
base.plot_original_y(x_avoidance.numpy(), ylabel='Cumulative Avoidances')
base.plot_original_y(x_shocked.numpy(), ylabel='Cumulative Shocked Trials')
x_avoidance: torch.Size([30, 25]), x_shocked: torch.Size([30, 25]), y: torch.Size([30, 25])
Sample x_avoidance: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 1., 1., 1., 1.,
1., 1., 1., 1., 2., 2., 3.])
Sample x_shocked: tensor([ 0., 1., 2., 3., 4., 5., 6., 7., 8., 8., 9., 10., 11., 12.,
13., 14., 15., 16., 17., 18., 19., 20., 20., 21., 21.])
The original data is not revealing much; looking at the cumulative avoidances and shocks, we see that some dogs never learn (example: Dog 1-4), and some dogs learn and retain the learning behaviour (example: Dog 25-30).
2. Model Specification¶
The sampling distribution of the generative model, as indicated earlier is:
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\log(\pi_{ij}) = \alpha x_{ij} + \beta\ ({j-x_{ij}})\)
Here, \(y_{ij}=1\) if the \(i^{th}\) dog fails to avoid a shock at the \(j^{th}\) trial, and is 0 if it avoids.
The above expression is used as a generalised linear model with log-link function in WinBugs implementation
BUGS model¶
In WinBUGs, the model is:
\(\log(\pi_{j}) = \alpha x_{j} + \beta({j-x_{j}})\)
Here
\(\log\pi_j\) is log probability of a dog getting shocked at trial \(j\).
\(x_j\) is the number of successful avoidances of shock prior to trial \(j\).
\(j-x_j\) is the number of shocks experienced prior to trial \(j\).
\(\alpha\) & \(\beta\) are the unknowns.
Following code block is from original BUGS volume:
{
for (i in 1 : Dogs) {
xa[i, 1] <- 0; xs[i, 1] <- 0 p[i, 1] <- 0
for (j in 2 : Trials) {
xa[i, j] <- sum(Y[i, 1 : j - 1])
xs[i, j] <- j - 1 - xa[i, j]
log(p[i, j]) <- alpha * xa[i, j] + beta * xs[i, j]
y[i, j] <- 1 - Y[i, j]
y[i, j] ~ dbern(p[i, j])
}
}
alpha ~ dnorm(0, 0.00001)I(, -0.00001)
beta ~ dnorm(0, 0.00001)I(, -0.00001)
A <- exp(alpha)
B <- exp(beta)
}
Stan model¶
The same model in PyStan is implemented as follows:
{
alpha ~ normal(0.0, 316.2);
beta ~ normal(0.0, 316.2);
for(dog in 1:Ndogs)
for (trial in 2:Ntrials)
y[dog, trial] ~ bernoulli(exp(alpha * xa[dog, trial] + beta * xs[dog, trial]));
}
In the orginal WinBUGS reference, \(\alpha, \beta\) are given truncated Normal priors, but not in Stan. Note that \(\pi_{ij} > 1\) when \(\alpha, \beta > 0\). Thefore, we have to restrict \(\alpha, \beta \le 0\)
Consequently, we elicit half-normal priors for \(\alpha,\beta\) with zero mean and large variance (flat) to complete the specification. Also notice that, the above model is in a more familiar form (Generalized Linear Model or Log-Linear Model). For convenience, we can define \(X_{a}\equiv x_{ij},\ X_{s}\equiv j-x_{ij} \)
The complete model is:
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\log(\pi_{ij}) = \alpha X_{a} + \beta X_{s}\)
or
\(\pi_{ij} = e^{(\alpha X_{a} + \beta X_{s})}\)
\(\alpha \sim N(0., 316.)I(\alpha <0)\)
\(\beta \sim N(0., 316.)I(\beta <0)\)
But it is easier to constrain R.Vs on the positive real line. So, we simply absorb the negative sign inside the model. Finally, we have these models, with Half-normal and Uniform priors s.t \(\alpha, \beta > 0\). They are:
Model A.
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = e^{(-(\alpha X_{a} + \beta X_{s}))}\)
\(\alpha \sim N(0., 316.)\ I(\alpha>0)\)
\(\beta \sim N(0., 316.)\ I(\beta>0)\)
Model B.
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = e^{(-(\alpha X_{a} + \beta X_{s}))}\)
\(\alpha \sim U(0, 10.)\)
\(\beta \sim U(0, 10.)\)
Model implementation¶
The above models are defined in base.DogsModel
DogsModel= base.DogsModel
DogsModel
<function chapter01.base.DogsModel(x_avoidance, x_shocked, y, alpha_prior=None, beta_prior=None, activation='exp')>
Let us also draw few samples from the prior, and look at the distribution
num_samples = 1100
alpha_prior_a, beta_prior_a= base.init_priors({"default":dist.HalfNormal(316.)})# Pass priors for model A
prior_samples_a = base.get_prior_samples(alpha_prior_a, beta_prior_a, num_samples=num_samples)
alpha_prior_b, beta_prior_b= base.init_priors({"default":dist.Uniform(0.001, 10)})# Pass uniform priors for model B
prior_samples_b = base.get_prior_samples(alpha_prior_b, beta_prior_b, num_samples=num_samples)
Sampled output of prior values for \(\alpha\) & \(\beta\) are stored in prior_samples above, and are plotted on a KDE plot as follows:
base.plot_prior_distributions(model_halfnormal_a= prior_samples_a, model_uniform_b= prior_samples_b)
For model 'model_halfnormal_a' Prior alpha Q(0.5) :206.15262603759766 | Prior beta Q(0.5) :206.13883209228516
For model 'model_uniform_b' Prior alpha Q(0.5) :5.179362535476685 | Prior beta Q(0.5) :5.287136554718018
3. Prior predictive checking¶
Prior predictive checking (PiPC)
original_plus_simulated_prior_data = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"], num_dogs=30, num_trials=24,
activation_type= "exp", model_halfnormal_a= prior_samples_a,
model_uniform_b= prior_samples_b)
___________
For model 'model_halfnormal_a' prior
total samples count: 1100 sample example: [(208.98727416992188, 84.3480224609375), (19.490013122558594, 196.33627319335938)]
Total execution time: 75.1559419631958
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_halfnormal_a' : (25,)
___________
For model 'model_uniform_b' prior
total samples count: 1100 sample example: [(5.8912200927734375, 0.18410980701446533), (7.265109539031982, 2.5937607288360596)]
Total execution time: 74.87336492538452
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_uniform_b' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (3, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from prior of 'model_halfnormal_a', 'Dog_2' corresponds to observations simulated from prior of 'model_uniform_b' & 'Dog_3' corresponds to 'Original data'.
We notice something very strange. We thought the priors on \(\alpha, \beta\) are flat, which is true, but naively we assumed they will turn out to be non-informative as well.
But they are not non-informative. In fact, they are extremely informative for \(\pi_{ij}\), since a priori, it has a right skewed distribution, with mode at 0. As a result, a priori, we think that, Dogs getting shocked has a very low chance.
Lets investigate it little more formally. Say, we observed \(X_a=1, X_s=0\), and also consider uniform priors \(U(0,b), b>0\) for both \(\alpha,\beta\).
Then, \(\pi = e^{-\alpha}\) with \(\alpha \sim U(0,b)\). We can calculate the prior expected value analytically, as follows:
with \(\lim_{b \to 0} E_{pr}[\hat{y}] = 1 \) and \(\lim_{b \to \infty} E_{pr}[\hat{y}] = 0 \) implying that, for supposedly a non-informative prior, we have strong prior belief that Dogs will avoid shocks, with certainity.
Let us generalize the setting further. Suppose, we are at the n-th trial. Let \(x_a, \ x_s\) be the avoidances and shocks upto this trial, respectively. Then,
Notice that, as the number of trials \(n = x_a+x_s+1\) increases, the expected values decreases to 0 at rate \(O(1/b^2n)\). Thefore, eventually, Dogs learn-to-avoid with certainty, is the a priori behaviour.
4. Posterior Estimation¶
In the Bayesian setting, inference is drawn from the posterior. Here, posterior implies the updated beliefs about the random variables, in the wake of given evidences (data). Formally,
\(Posterior = \frac {Likelihood x Prior}{Probability \ of Evidence}\)
In our case, \(\alpha,\beta\) are the parameters (actually random variables) & \(y\) is the evidence; According to the Bayes rule, Posterior \(P(\alpha,\beta | y)\) is given as:
\(P\ (\alpha,\beta | y) = \frac {P(y | \alpha,\beta) \pi(\alpha,\beta)}{P(y)}\)
Now our interest is in estimating the posterior summaries of the parameters \(\alpha, \beta\). For example, we can look at the posterior of mean of \(\alpha\), denoted as \(E(\alpha)\). However, in order to the get the posterior quanitities, either we need to compute the integrals or approximate the integrals via Markov Chain Monte Carlo.
The latter can be easily accomplished in Pyro by using the NUTS sampler – NUTS is a specific sampler designed to draw samples efficiently from the posterior using Hamiltonian Monte Carlo dynamics.
The following code snippet takes a pyro model object with – posterior specification, input data, some configuration parameters such as a number of chains and number of samples per chain. It then launches a NUTS sampler and produces MCMC samples in a python dictionary format.
# DogsModel_A alpha, beta ~ HalfNormal(316.) & activation "exp"
hmc_sample_chains_a, hmc_chain_diagnostics_a = base.get_hmc_n_chains(DogsModel, x_avoidance, x_shocked, y, num_chains=4,
sample_count = 900, alpha_prior= dist.HalfNormal(316.),
beta_prior= dist.HalfNormal(316.), activation= "exp")
Sample: 100%|██████████| 11000/11000 [00:51, 213.95it/s, step size=9.31e-01, acc. prob=0.909]
Sample: 100%|██████████| 11000/11000 [00:42, 257.06it/s, step size=9.47e-01, acc. prob=0.881]
Sample: 100%|██████████| 11000/11000 [00:53, 205.76it/s, step size=7.71e-01, acc. prob=0.915]
Sample: 100%|██████████| 11000/11000 [00:53, 204.40it/s, step size=8.01e-01, acc. prob=0.928]
Total time: 202.18049597740173
# DogsModel_B alpha, beta ~ Uniform(0., 10.0) & activation "exp"
hmc_sample_chains_b, hmc_chain_diagnostics_b = base.get_hmc_n_chains(DogsModel, x_avoidance, x_shocked, y, num_chains=4, sample_count = 900,
alpha_prior= dist.Uniform(0., 10.0), beta_prior= dist.Uniform(0., 10.0), activation= "exp")
Sample: 100%|██████████| 11000/11000 [00:50, 218.81it/s, step size=7.54e-01, acc. prob=0.927]
Sample: 100%|██████████| 11000/11000 [00:48, 224.73it/s, step size=7.89e-01, acc. prob=0.927]
Sample: 100%|██████████| 11000/11000 [00:49, 221.43it/s, step size=8.69e-01, acc. prob=0.916]
Sample: 100%|██████████| 11000/11000 [00:40, 273.05it/s, step size=9.71e-01, acc. prob=0.897]
Total time: 189.7234182357788
hmc_sample_chains holds sampled MCMC values as {"Chain_0": {alpha [-0.20020795, -0.1829252, -0.18054989 . .,], "beta": {}. .,}, "Chain_1": {alpha [-0.20020795, -0.1829252, -0.18054989 . .,], "beta": {}. .,}. .}
5. MCMC Diagnostics¶
Diagnosing the computational approximation
Just like any numerical technique, no matter how good the theory is or how robust the implementation is, it is always a good idea to check if indeed the samples drawn are reasonable. In the ideal situation, we expect the samples drawn by the sampler to be independant, and identically distributed (i.i.d) as the posterior distribution. In practice, this is far from true as MCMC itself is an approximate technique and a lot can go wrong. In particular, chains may not have converged or samples are very correlated. We can divide diagnosis into three sections.
Burn-in: What is the effect of initialization? By visually inspecting the chains, we can notice the transient behaviour. We can drop the first “n” number of samples from the chain.
Thinning: What is the intra chain correlation? We can use ACF (Auto-correlation function) to inspect it. A rule of thumb is, thin the chains such that, the ACF drops to \(1/10^{th}\). Here, ACF drops to less than 0.1 at lag 5, then we retain only every \(5^{th}\) sample in the chain.
Mixing: Visually, all the chains, when plotted, should be indistinguishable from each other. At a very broad level, the means of the chains and variances shall be close. These are the two central moments we can track easily and turn them into Gelman-Rubin statistic. Other summmary statistics can be tracked, of course.
We can use both visual and more formal statistical techniques to inspect the quality of the fit (not the model fit to the data, but how well the approximation is, having accepted the model class for the data at hand) by treating chains as time-series data, and that we can run several chains in parallel. We precisely do that next.
Following snippet allows plotting Parameter vs. Chain matrix and optionally saving the dataframe.
Model-A Summaries¶
# Unpruned sample chains for model A with HalfNormal prior
beta_chain_matrix_df_A = pd.DataFrame(hmc_sample_chains_a)
base.save_parameter_chain_dataframe(beta_chain_matrix_df_A, "data/dogs_parameter_chain_matrix_1A.csv")
Saved at 'data/dogs_parameter_chain_matrix_1A.csv'
A.1 Visual summary¶
A.1.1 Intermixing chains¶
Sample chains mixing for HalfNormal priors.
Following plots chains of samples for alpha & beta parameters for model_HalfNormal_a
base.plot_chains(beta_chain_matrix_df_A)
for chain, samples in hmc_sample_chains_a.items():
print("____\nFor 'model_HalfNormal_a' %s"%chain)
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))


____
For 'model_HalfNormal_a' chain_0
chain_0 Sample count: 10000
Alpha Q(0.5) :tensor(0.1936) | Beta Q(0.5) :tensor(0.0073)
____
For 'model_HalfNormal_a' chain_1
chain_1 Sample count: 10000
Alpha Q(0.5) :tensor(0.1938) | Beta Q(0.5) :tensor(0.0073)
____
For 'model_HalfNormal_a' chain_2
chain_2 Sample count: 10000
Alpha Q(0.5) :tensor(0.1937) | Beta Q(0.5) :tensor(0.0073)
____
For 'model_HalfNormal_a' chain_3
chain_3 Sample count: 10000
Alpha Q(0.5) :tensor(0.1935) | Beta Q(0.5) :tensor(0.0073)
A.2 Quantitative summary¶
A.2.1 ACF plots¶
Auto-correlation plots for sample chains with HalfNormal priors
base.autocorrelation_plots(beta_chain_matrix_df_A)
For
alpha,thining factorforchain_0is 3,chain_1is 3,chain_2is 3,chain_3is 3For
beta,thinin factorforchain_0is 3,chain_1is 3,chain_2is 3,chain_3is 3
Pruning chains from model with HalfNormal priors
thining_dict_a = {"chain_0": {"alpha":3, "beta":3}, "chain_1": {"alpha":3, "beta":3},
"chain_2": {"alpha":3, "beta":3}, "chain_3": {"alpha":3, "beta":3}}
pruned_hmc_sample_chains_a = base.prune_hmc_samples(hmc_sample_chains_a, thining_dict_a)
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_0' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_0' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_1' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_1' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_2' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_2' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_3' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_3' parameters: {'alpha': (3333,), 'beta': (3333,)}
A.2.2 G-R statistic¶
Gelman-Rubin statistic for chains with HalfNormal priors
grubin_values_a = base.gelman_rubin_stats(pruned_hmc_sample_chains_a)
Gelmen-rubin for 'param' alpha all chains is: 0.9997
Gelmen-rubin for 'param' beta all chains is: 0.9998
A.3 Descriptive summary¶
Following outputs the summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", select names of statistic metric from given list to view values.
A.3.1 Summary Table 1¶
Tabulated Summary for model chains with HalfNormal priors
#chain results Pruned after ACF plots
beta_chain_matrix_df_A = pd.DataFrame(pruned_hmc_sample_chains_a)
base.summary(beta_chain_matrix_df_A)
Select any value
We can also report the 5-point Summary Statistics (mean, Q1-Q4, Std, ) as tabular data per chain and save the dataframe
fit_df_A = pd.DataFrame()
for chain, values in pruned_hmc_sample_chains_a.items():
param_df = pd.DataFrame(values)
param_df["chain"]= chain
fit_df_A= pd.concat([fit_df_A, param_df], axis=0)
base.save_parameter_chain_dataframe(fit_df_A, "data/dogs_classification_hmc_samples_1A.csv")
Saved at 'data/dogs_classification_hmc_samples_1A.csv'
Use following button to upload:
"data/dogs_classification_hmc_samples_1A.csv"as'fit_df_A'
# Use following to load data once the results from pyro sampling operation are saved offline
load_button= base.build_upload_button()
# Use following to load data once the results from pyro sampling operation are saved offline
if load_button.value:
fit_df_A = base.load_parameter_chain_dataframe(load_button)#Load "data/dogs_classification_hmc_samples_1A.csv"
A.3.2 Summary Table 2¶
5-point Summary Statistics for model chains with HalfNormal priors
Following outputs the similar summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", but in a slightly different format, given a list of statistic names
base.summary(fit_df_A, layout =2)
Select any value
Following plots sampled parameters values as Boxplots with M parameters side by side on x axis for each of the N chains.
Pass the list of M parameters and list of N chains, with plot_interactive as True or False to choose between Plotly or Seaborn
A.4 Additional plots¶
A.4.1 Boxplots¶
Boxplot for model chains with HalfNormal priors
parameters= ["alpha", "beta"]# All parameters for given model
chains= fit_df_A["chain"].unique()# Number of chains sampled for given model
# Use plot_interactive=False for Normal seaborn plots offline
base.plot_parameters_for_n_chains(fit_df_A, chains=['chain_0', 'chain_1', 'chain_2', 'chain_3'], parameters=parameters, plot_interactive=True)
A.4.2 Joint distribution plots¶
Following plots the joint distribution of pair of each parameter sampled values for all chains with HalfNormal priors.
base.plot_joint_distribution(fit_df_A, parameters)
Pyro -- alpha Vs. beta

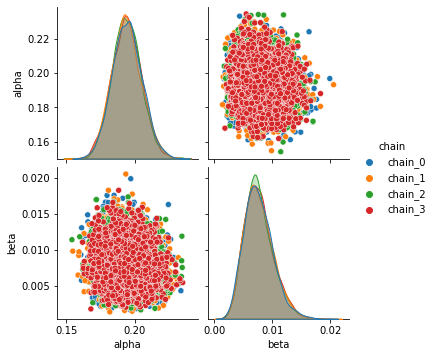
A.4.3 Pairplots¶
Following plots the Pairplot distribution of each parameter with every other parameter’s sampled values for all chains with HalfNormal priors
sns.pairplot(data=fit_df_A, hue= "chain");

Model-B Summaries¶
# Unpruned sample chains for model B with Uniform prior
beta_chain_matrix_df_B = pd.DataFrame(hmc_sample_chains_b)
base.save_parameter_chain_dataframe(beta_chain_matrix_df_B, "data/dogs_parameter_chain_matrix_1B.csv")
Saved at 'data/dogs_parameter_chain_matrix_1B.csv'
B.1 Visual summary¶
B.1.1 Intermixing chains¶
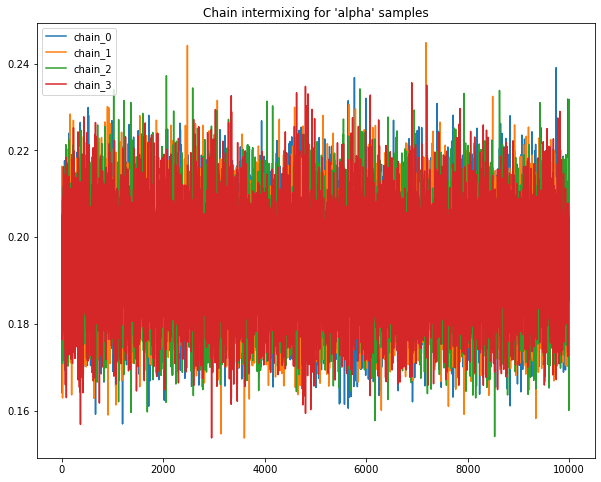
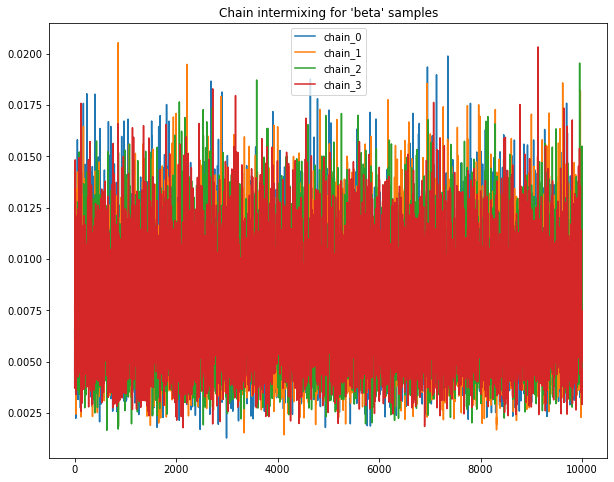
Sample chains mixing for Uniform priors.
Following plots chains of samples for alpha & beta parameters for model_Uniform_b
base.plot_chains(beta_chain_matrix_df_B)
for chain, samples in hmc_sample_chains_b.items():
print("____\nFor 'model_Uniform_b' %s"%chain)
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))
____
For 'model_Uniform_b' chain_0
chain_0 Sample count: 10000
Alpha Q(0.5) :tensor(0.1938) | Beta Q(0.5) :tensor(0.0073)
____
For 'model_Uniform_b' chain_1
chain_1 Sample count: 10000
Alpha Q(0.5) :tensor(0.1935) | Beta Q(0.5) :tensor(0.0074)
____
For 'model_Uniform_b' chain_2
chain_2 Sample count: 10000
Alpha Q(0.5) :tensor(0.1934) | Beta Q(0.5) :tensor(0.0073)
____
For 'model_Uniform_b' chain_3
chain_3 Sample count: 10000
Alpha Q(0.5) :tensor(0.1936) | Beta Q(0.5) :tensor(0.0074)
B.2 Quantitative summary¶
B.2.1 ACF plots¶
Auto-correlation plots for sample chains with Uniform priors
base.autocorrelation_plots(beta_chain_matrix_df_B)
For
alpha,thining factorforchain_0is 3,chain_1is 3,chain_2is 3,chain_3is 3For
beta,thinin factorforchain_0is 3,chain_1is 3,chain_2is 3,chain_3is 3
Pruning chains from model with Uniform priors
thining_dict_b = {"chain_0": {"alpha":3, "beta":3}, "chain_1": {"alpha":3, "beta":3},
"chain_2": {"alpha":3, "beta":3}, "chain_3": {"alpha":3, "beta":3}}
pruned_hmc_sample_chains_b = base.prune_hmc_samples(hmc_sample_chains_b, thining_dict_b)
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_0' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_0' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_1' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_1' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_2' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_2' parameters: {'alpha': (3333,), 'beta': (3333,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_3' parameters: {'alpha': 3, 'beta': 3}
Post thining sample counts for 'chain_3' parameters: {'alpha': (3333,), 'beta': (3333,)}
B.2.2 G-R statistic¶
Gelman-Rubin statistic for chains with Uniform priors
grubin_values_b = base.gelman_rubin_stats(pruned_hmc_sample_chains_b)
Gelmen-rubin for 'param' alpha all chains is: 0.9998
Gelmen-rubin for 'param' beta all chains is: 0.9997
B.3 Descriptive summary¶
Following outputs the summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", select names of statistic metric from given list to view values
B.3.1 Summary Table 1¶
Tabulated Summary for model chains with Uniform priors
#chain results Pruned after ACF plots
beta_chain_matrix_df_B = pd.DataFrame(pruned_hmc_sample_chains_b)
base.summary(beta_chain_matrix_df_B)
Select any value
We can also report the 5-point Summary Statistics (mean, Q1-Q4, Std, ) as tabular data per chain and save the dataframe
fit_df_B = pd.DataFrame()
for chain, values in pruned_hmc_sample_chains_b.items():
param_df = pd.DataFrame(values)
param_df["chain"]= chain
fit_df_B= pd.concat([fit_df_B, param_df], axis=0)
base.save_parameter_chain_dataframe(fit_df_B, "data/dogs_classification_hmc_samples_1B.csv")
Saved at 'data/dogs_classification_hmc_samples_1B.csv'
Use following button to upload:
"data/dogs_classification_hmc_samples_1B.csv"as'fit_df_B'
# Use following to load data once the results from pyro sampling operation are saved offline
load_button= base.build_upload_button()
# Use following to load data once the results from pyro sampling operation are saved offline
if load_button.value:
fit_df_B= base.load_parameter_chain_dataframe(load_button)#Load "data/dogs_classification_hmc_samples_1B.csv"
B.3.2 Summary Table 2¶
5-point Summary Statistics for model chains with Uniform priors
Following outputs the similar summary of required statistics such as "mean", "std", "Q(0.25)", "Q(0.50)", "Q(0.75)", but in a slightly different format, given a list of statistic names
base.summary(fit_df_B, layout =2)
Select any value
Following plots sampled parameters values as Boxplots with M parameters side by side on x axis for each of the N chains.
Pass the list of M parameters and list of N chains, with plot_interactive as True or False to choose between Plotly or Seaborn
B.4 Additional plots¶
B.4.1 Boxplots¶
Boxplot for model chains with Uniform priors
parameters= ["alpha", "beta"]# All parameters for given model
chains= fit_df_B["chain"].unique()# Number of chains sampled for given model
# Use plot_interactive=False for Normal seaborn plots offline
base.plot_parameters_for_n_chains(fit_df_B, chains=['chain_0', 'chain_1', 'chain_2', 'chain_3'], parameters=parameters, plot_interactive=True)
B.4.2 Joint distribution plots¶
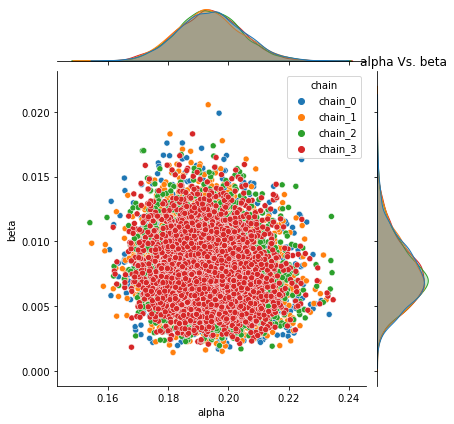
Following plots the joint distribution of pair of each parameter sampled values for all chains with Uniform priors.
base.plot_joint_distribution(fit_df_B, parameters)
Pyro -- alpha Vs. beta
B.4.3 Pairplots¶
Following plots the Pairplot distribution of each parameter with every other parameter’s sampled values for all chains with Uniform priors
sns.pairplot(data=fit_df_B, hue= "chain");
Combined KDE plots¶
Kernel density plots for model_HalfNormal_a & model_Uniform_b
for chain in hmc_sample_chains_a.keys():
print("____\nFor 'model_HalfNormal_a' & 'model_Uniform_b' %s"%chain)
chain_list= list(hmc_sample_chains_a[chain].values())
chain_list.extend(list(hmc_sample_chains_b[chain].values()))
title= "parameter distribution for : %s"%(chain)
fig = ff.create_distplot(chain_list, ["alpha_a", "beta_a", "alpha_b", "beta_b"])
fig.update_layout(title=title, xaxis_title="parameter values", yaxis_title="density", legend_title="parameters")
fig.show()
break
____
For 'model_HalfNormal_a' & 'model_Uniform_b' chain_0
Nothing unusual seems to be happening.
All chains are mixing well (G-R statistics are close to 1).
ACF of the chains decay rapidly.
Both Half-normal and Uniform are giving similar results
Joint distribution of \(\alpha, \beta\) has no strong correlation, and are consistent across chains.
But, let us do Posterior Predictive checks
6. Sensitivity Analysis¶
Posterior Predictive Checking (PoPC) helps examine the fit of a model to real data. The simulation parameters come from the posterior distribution. While PoPC incorporates model uncertainly (by averaging over all possible models), we take a simpler route to begin with, which is to sample the \(\alpha, \beta\) pairs that are very plausible in the posterior (eg. the posterior means), and simulate data under this particular generative model.
In particular, just like the PiPC (Prior Predictive Check), we are intereted in the posterior expected value of a Dog getting shocked. This quantity can be estimated by the Monte Carlo average:
where \(\alpha_t, \beta_t\) are the t-th posterior samples in the MCMC chain.
# With priors & posteriros
posterior_parameters_pairs_a = pruned_hmc_sample_chains_a.get('chain_0')
posterior_parameters_pairs_b = pruned_hmc_sample_chains_b.get('chain_0')
original_plus_simulated_data_posterior = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"],
num_dogs=30, num_trials=24, activation_type= "exp",
prior_simulations= original_plus_simulated_prior_data,
model_halfnormal_a= posterior_parameters_pairs_a,
model_uniform_b= posterior_parameters_pairs_b)
___________
For model 'model_halfnormal_a' posterior
total samples count: 3333 sample example: [(0.20342435, 0.0077009345), (0.19606128, 0.008753207)]
Total execution time: 233.4701588153839
Number of datasets/posterior pairs generated: 3333
Shape of data simulated from posterior for model 'model_halfnormal_a' : (25,)
___________
For model 'model_uniform_b' posterior
total samples count: 3333 sample example: [(0.2120226, 0.0045217406), (0.194261, 0.008113162)]
Total execution time: 232.12142419815063
Number of datasets/posterior pairs generated: 3333
Shape of data simulated from posterior for model 'model_uniform_b' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (5, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from posterior of 'model_halfnormal_a', 'Dog_2' corresponds to observations simulated from posterior of 'model_uniform_b', 'Dog_3' corresponds to observations simulated from prior of 'model_halfnormal_a', 'Dog_4' corresponds to observations simulated from prior of 'model_uniform_b' & 'Dog_5' corresponds to 'Original data'.
original_plus_simulated_data_posterior_df= pd.DataFrame(original_plus_simulated_data_posterior.T,
columns=["Dog_%s"%(idx+1) for idx in range(len(original_plus_simulated_data_posterior))])
base.save_parameter_chain_dataframe(original_plus_simulated_data_posterior_df,
"data/dogs_original_plus_simulated_data_model_1ab.csv")
Saved at 'data/dogs_original_plus_simulated_data_model_1ab.csv'
Something weird happenning! The posterior expected value of a Dog getting shocked is larger than the prior, and also the observed data.
We anticipate the posterior expected value to lie between data and prior, some sort of a weighed average of prior and data. Why is this not happenning? Let us investigate.
Can we compute the posterior, and prior expectations analytically to prove the point? Since sampling distribution and prior for \(\alpha, \beta\) are not conjugate, in general, we can not analytically compute them. At least, it is not trivial. But we will simplify the situation, just to gain insights into the problem.
Say, we observed \(X_a=1, X_s=0, y=1\), and also consider uniform priors \(U(0,b), b>0\) for both \(\alpha,\beta\).
Then, \(\pi = e^{-\alpha}\) with \(\alpha \sim U(0,b)\). Earlier, we calculated the prior expected value analytically as \(E_{pr}[\hat{y}] = (1-e^{-b})/b\)
Likewise, posteriror expected value can be caluclated at the second trial. But before that, we need to calculate the posterior distribution. Assume that, we observed \(y=1\). Then,
\(P(\alpha,\beta | y=1, X_a=1, X_s=0) \propto e^{-\alpha} I(0,b)\) \(\implies\) \(E_{po}(\hat{y} | y=1, X_a=1, X_s=0)= \frac{1}{1-e^{-b}}\int_0^{b} e^{-2\alpha} = \frac{0.5(1-e^{-2b})}{1-e^{-b}}\)
Since we know \(y=1\), hypothesis is \( \frac{0.5(1-\exp(-2b))}{1-\exp(-b)} \le 1-\exp(-b)\). Let us verify if this inquality is true. At least for \(b >> 1\) large, say \(b=10, \exp(-b) \approx 0\). Therefore, for flat prior, \( 0.5 \le 1\), which is true. We will not prove but, we anticipate the same behaviour being true for any observed data. Let us verify the asymptotic behaviour a little bit.
Consider that, we have data about all dogs upto time \(t\), and there are \(n\) Dogs. The likelihood is:
\(L(y | \alpha,\beta) = \prod_{i=1}^{n} \pi^{y_i} (1-\pi_i)^{1-y_i} \), with \(\pi_i = e^{-(x_{i,a}^t \alpha + x_{i,s}^t \beta)}\), \(x_{i,s}(t), x_{i,a}(t)\) are cumulative avoidances and shocks of the i-th dog, upto time \(t\). We divide the responses into two sets: Dogs that are shocked and those that are not into \(S\) and \(S^c\), respectively.
Then likelihood simplifies to:
It can be further simplified by absorbing few more summary statistics into it as:
where \(N_a = \sum_{j=1, i \in S^c}^{t} x_{i,a}(j) \). Others can be defined similarly.
Now the posterior at time t, can be defined as follows:
which turns out to be, after some algebra,
where the normalization constant \(Z\) is \(\frac{1}{(1-e^{-bN_a})(1-e^{-bN_s})} - \frac{1}{(1-e^{-b(N_a+M_a)})(1-e^{-b(N_s+M_s)})}\)
The expected response under the above posterior is: \(E_{P(\alpha, \beta | data)}[\hat{y}] = E[e^{-(\alpha x_a + \beta x_s)}]\) for some given \(x_a,\ x_s\). After some algebra, we get
Even when the data shows strong tendency for Dogs to not learn from shocks, i.e, \(|S| >> |S^c|\). Asymptotically, \(\lim_{N_s \to \infty} E_{P(\alpha, \beta | data)}[\hat{y}] = 0\). We suspect that, the rate is much slower than the prior. Consequently, the posterior expected value will sit above the prior but below the empirical average, at the last trial.
Now we detected a problem. What could be happenning? Few plausible explanations are as follows:
Recall that the prior was very informative (very strong prior on Dogs getting shocked) but data is far from it. There is a mismatch between data and prior.
Even the posterior, it appears, is strongly influenced by the characterization (model).
Upon inspection, we realized that the
pyrosampler draws samples around 0 during initialization. Which in this case means that initialization is very far from both the prior and the posterior. Consequently, the posterior landscape could be very rugged, NUTS struggles to get out of the sampling zone.Notice that the prior and posterior asymptotic analysis was carried out at the last trial. But, the joint likelihood is defined over horizon of the entire trials. As a result, posterior expectation at an intermediate trial has already seen the future data (more like smoothening). Consequently, it may be possible that, the posterior and prior wont agree becuase of the data-leakage.
Model with offset prior¶
Pass the offset value 4 to the likelihood function of DogsModel and perform both prior & posterior predictive checks with updated model, using respective prior distribution \(\alpha, \beta \sim N(0., 316.)\ I(\alpha>0)\) and \(\alpha, \beta \sim U(0, 10.)\) in similar manner.
The offset models are therefore defined as follows:
Model A (offset)
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = e^{(-((\alpha+\ 4) X_{a} + (\beta+\ 4) X_{s}))}\)
Model B (offset)
\(y_{ij} \sim Bern(\pi_{ij})\)
\(\pi_{ij} = e^{(-((\alpha+\ 4) X_{a} + (\beta+\ 4) X_{s}))}\)
prior_offset=4
original_plus_simulated_prior_data_offset = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"], num_dogs=30, num_trials=24,
activation_type= "exp", prior_offset=prior_offset,
model_halfnormal_a_off= prior_samples_a,
model_uniform_b_off= prior_samples_b)
___________
For model 'model_halfnormal_a_off' prior
total samples count: 1100 sample example: [(208.98727416992188, 84.3480224609375), (19.490013122558594, 196.33627319335938)]
Total execution time: 76.99121570587158
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_halfnormal_a_off' : (25,)
___________
For model 'model_uniform_b_off' prior
total samples count: 1100 sample example: [(5.8912200927734375, 0.18410980701446533), (7.265109539031982, 2.5937607288360596)]
Total execution time: 76.48529696464539
Number of datasets/prior pairs generated: 1100
Shape of data simulated from prior for model 'model_uniform_b_off' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (3, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from prior of 'model_halfnormal_a_off', 'Dog_2' corresponds to observations simulated from prior of 'model_uniform_b_off' & 'Dog_3' corresponds to 'Original data'.
Now in order to validate the suspected issue with pyro initialisation, we shall run the NUTS sampler again with new DogsModel with the provision of priors offset by a value say 4, from the initial values around 0. We shall proceed to repeat steps for both models- ‘Model_a’ with HalfNormal prior distritbution and alternate ‘Model_b’ with Uniform priors.
DogsModel_offset = base.DogsModel_
hmc_sample_chains_a_off, hmc_chain_diagnostics_a_off = base.get_hmc_n_chains(DogsModel_offset, x_avoidance, x_shocked, y, num_chains=4,
sample_count = 900, alpha_prior= dist.HalfNormal(316.),
beta_prior= dist.HalfNormal(316.), activation= "exp")
beta_chain_matrix_df_A_off = pd.DataFrame(hmc_sample_chains_a_off)
Sample: 100%|██████████| 11000/11000 [01:11, 154.92it/s, step size=5.32e-01, acc. prob=0.932]
Sample: 100%|██████████| 11000/11000 [01:13, 150.38it/s, step size=4.68e-01, acc. prob=0.946]
Sample: 100%|██████████| 11000/11000 [01:01, 178.10it/s, step size=5.12e-01, acc. prob=0.894]
Sample: 100%|██████████| 11000/11000 [01:05, 168.96it/s, step size=5.93e-01, acc. prob=0.924]
Total time: 271.8832468986511
# DogsModel_B alpha, beta ~ Uniform(0., 10.0) & activation "exp"
hmc_sample_chains_b_off, hmc_chain_diagnostics_b_off = base.get_hmc_n_chains(DogsModel_offset, x_avoidance, x_shocked, y, num_chains=4,
sample_count = 900, alpha_prior= dist.Uniform(0., 10.0),
beta_prior= dist.Uniform(0., 10.0), activation= "exp")
beta_chain_matrix_df_B_off = pd.DataFrame(hmc_sample_chains_b_off)
Sample: 100%|██████████| 11000/11000 [00:57, 190.26it/s, step size=5.74e-01, acc. prob=0.911]
Sample: 100%|██████████| 11000/11000 [00:56, 196.24it/s, step size=6.09e-01, acc. prob=0.888]
Sample: 100%|██████████| 11000/11000 [01:00, 181.65it/s, step size=5.47e-01, acc. prob=0.925]
Sample: 100%|██████████| 11000/11000 [01:03, 172.40it/s, step size=4.86e-01, acc. prob=0.943]
Total time: 238.94750881195068
For performing the Posterior predictive checks on new samples we shall obtain ACF and thereby prune the chains for Model A and Model B.
base.autocorrelation_plots(beta_chain_matrix_df_A_off)
base.autocorrelation_plots(beta_chain_matrix_df_B_off)
thining_dict_a_off = {"chain_0": {"alpha":4, "beta":4}, "chain_1": {"alpha":4, "beta":4},
"chain_2": {"alpha":4, "beta":4}, "chain_3": {"alpha":4, "beta":4}}
thining_dict_b_off = thining_dict_a_off
pruned_hmc_sample_chains_a_off = base.prune_hmc_samples(hmc_sample_chains_a_off, thining_dict_a_off)
pruned_hmc_sample_chains_b_off = base.prune_hmc_samples(hmc_sample_chains_b_off, thining_dict_b_off)
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_0' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_0' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_1' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_1' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_2' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_2' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_3' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_3' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_0' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_0' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_0' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_1' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_1' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_1' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_2' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_2' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_2' parameters: {'alpha': (2500,), 'beta': (2500,)}
-------------------------
Original sample counts for 'chain_3' parameters: {'alpha': (10000,), 'beta': (10000,)}
Thining factors for 'chain_3' parameters: {'alpha': 4, 'beta': 4}
Post thining sample counts for 'chain_3' parameters: {'alpha': (2500,), 'beta': (2500,)}
posterior_parameters_pairs_a_off = pruned_hmc_sample_chains_a_off.get('chain_0')
posterior_parameters_pairs_b_off = pruned_hmc_sample_chains_b_off.get('chain_0')
original_plus_simulated_data_posterior_off = base.simulate_observations_given_prior_posterior_pairs(dogs_data["Y"],
num_dogs=30, num_trials=24, activation_type= "exp",
prior_offset=prior_offset,
prior_simulations= original_plus_simulated_prior_data_offset,
model_halfnormal_a_off= posterior_parameters_pairs_a_off,
model_uniform_b_off= posterior_parameters_pairs_b_off)
___________
For model 'model_halfnormal_a_off' posterior
total samples count: 2500 sample example: [(0.0151763875, 3.2821113e-06), (0.017246833, 0.0031679303)]
Total execution time: 176.4158971309662
Number of datasets/posterior pairs generated: 2500
Shape of data simulated from posterior for model 'model_halfnormal_a_off' : (25,)
___________
For model 'model_uniform_b_off' posterior
total samples count: 2500 sample example: [(0.06282045, 0.0018846309), (0.1121857, 0.011577433)]
Total execution time: 176.1145212650299
Number of datasets/posterior pairs generated: 2500
Shape of data simulated from posterior for model 'model_uniform_b_off' : (25,)
Respective shape of original data: (25,) and concatenated arrays of data simulated for different priors/posteriors: (5, 25)
_______________________________________________________
______________________________________________________________________
Here 'Dog_1' corresponds to observations simulated from posterior of 'model_halfnormal_a_off', 'Dog_2' corresponds to observations simulated from posterior of 'model_uniform_b_off', 'Dog_3' corresponds to observations simulated from prior of 'model_halfnormal_a_off', 'Dog_4' corresponds to observations simulated from prior of 'model_uniform_b_off' & 'Dog_5' corresponds to 'Original data'.
Despite not being able to follow the original data like previously, the plot seems to deliver well on our suspicion of faulty initialisation in former case; Here the Posteriror traces priors better with values offset from default pyro initialisation.
There are two take-ways from this analysis.
We need to set priors such that the intitializations, as preferred by
pyro, are around zero. The priors need to be caliberated in the model such that, the most plausible values or the central region should be around zero. We will offset the prior into a more negative region, and consider its effect on the sampler.The sampling distribution, in paritcular, the
loglink function, seems to be a poor choice. Instead, we could use asigmoidlink function. We will analyze the same data, with asigmoidlink function in the chapter 02.
7. Model Comparison¶
Ideally, we would not have proceeded with model comparison, as we originally envisioned, due to poor fit between model and data. However, for pedagogic reasons, and comppleness sake, we will do model comparison.
More often than not, there may be many plausible models that can explain the data. Sometime, the modeling choice is based on domain knowledge. Sometime it is out of comptational conveninece. Latter is the case with the choice of priors. One way to consider different models is by eliciting different prior distributions.
As long as the sampling distribtion is same, one can use Deviance Information Criterion (DIC) to guide model comparison.
DIC¶
DIC(Deviance Information Criterion) is computed as follows
\(D(\alpha,\beta) = -2\ \sum_{i=1}^{n} \log P\ (y_{i}\ /\ \alpha,\beta)\)
\(\log P\ (y_{i}\ /\ \alpha,\beta)\) is the log likehood of shocks/avoidances observed given parameter \(\alpha,\beta\), this expression expands as follows: $\(\begin{equation} D(\alpha,\beta) = -2\ \sum_{i=1}^{30}[ y_{i}\ (\alpha Xa_{i}\ +\beta\ Xs_{i}) + \ (1-y_{i})\log\ (1\ -\ e^{(\alpha Xa_{i}\ +\beta\ Xs_{i})})] \end{equation}\)$
Using $D(\alpha,\beta)$ to Compute DIC
\(\overline D(\alpha,\beta) = \frac{1}{T} \sum_{t=1}^{T} D(\alpha,\beta)\)
\(\overline \alpha = \frac{1}{T} \sum_{t=1}^{T}\alpha_{t}\\\) \(\overline \beta = \frac{1}{T} \sum_{t=1}^{T}\beta_{t}\)
\(D(\overline\alpha,\overline\beta) = -2\ \sum_{i=1}^{30}[ y_{i}\ (\overline\alpha Xa_{i}\ +\overline\beta\ Xs_{i}) + \ (1-y_{i})\log\ (1\ -\ e^{(\overline\alpha Xa_{i}\ +\overline\beta\ Xs_{i})})]\)
Therefore finally
Following method computes deviance value given parameters `alpha & beta`
#launch docstring for calculate_deviance_given_param
#launch docstring for calculate_mean_deviance
Following method computes deviance information criterion for a given bayesian model & chains of sampled parameters alpha & beta
#launch docstring for DIC
#launch docstring for compare_DICs_given_model
In Section 5., we already sampled alternate model to obtain posterior chains as pruned_hmc_sample_chains_b which we shall use for computing DIC in cells that follow.
compute & compare deviance information criterion for a multiple bayesian models
base.compare_DICs_given_model(x_avoidance, x_shocked, y, Dogs_HalfNormal_prior= pruned_hmc_sample_chains_a, Dogs_uniform_prior= pruned_hmc_sample_chains_b)
______________________________
For model : Dogs_HalfNormal_prior
. . .DIC for chain_0: 715.321
. . .DIC for chain_1: 715.321
. . .DIC for chain_2: 715.321
. . .DIC for chain_3: 715.321
. .Mean Deviance information criterion for all chains: 715.321
______________________________
For model : Dogs_uniform_prior
. . .DIC for chain_0: 715.321
. . .DIC for chain_1: 715.321
. . .DIC for chain_2: 715.321
. . .DIC for chain_3: 715.321
. .Mean Deviance information criterion for all chains: 715.321
The DIC values are very close, so we don’t anticipate substantially different fits. This is largely because, both priors are flat. However, if we were to follow the rule book, we had to pick a model with the smallest DIC. In this case, both Normal Priors & Uniform Priors yield identical DIC.
8. Inference & Analysis¶
Alright, we have a model, but so what? The purpose of model building is to use these models as probing devices. That is, using the models can we answer some questions about the reality that these models have abstracted.
We choose model with Half-Normal Prior, and pick samples from one particular chain of HMC samples say chain_3
for chain, samples in pruned_hmc_sample_chains_a.items():
samples= dict(map(lambda param: (param, torch.tensor(samples.get(param))), samples.keys()))# np array to tensors
print(chain, "Sample count: ", len(samples["alpha"]))
chain_0 Sample count: 3333
chain_1 Sample count: 3333
chain_2 Sample count: 3333
chain_3 Sample count: 3333
Plot density for parameters from chain_3 to visualise the spread of sample values from that chain
title= "parameter distribution for : %s"%(chain)
fig = ff.create_distplot(list(map(lambda x:x.numpy(), samples.values())), list(samples.keys()))
fig.update_layout(title=title, xaxis_title="parameter values", yaxis_title="density", legend_title="parameters")
fig.show()
print("Alpha Q(0.5) :%s | Beta Q(0.5) :%s"%(torch.quantile(samples["alpha"], 0.5), torch.quantile(samples["beta"], 0.5)))
Alpha Q(0.5) :tensor(0.1933) | Beta Q(0.5) :tensor(0.0073)
Plot density & contours for both parameters from chain_3 to visualise the joint distribution & region of interest with HalfNormal priors.
#Choosing samples from chain 3
chain_samples_df_A= fit_df_A[fit_df_A["chain"]==chain].copy()# chain is 'chain_3'
alpha= chain_samples_df_A["alpha"].tolist()
beta= chain_samples_df_A["beta"].tolist()
colorscale = ['#7A4579', '#D56073', 'rgb(236,158,105)', (1, 1, 0.2), (0.98,0.98,0.98)]
fig = ff.create_2d_density(alpha, beta, colorscale=colorscale, hist_color='rgb(255, 255, 150)', point_size=4, title= "Alpha-Beta joint density plot for model with 'HalfNormal' prior")
fig.update_layout( xaxis_title="x (alpha)", yaxis_title="y (beta)")
fig.show()
Observations:¶
On observing the joint distribution of \(\alpha, \beta\), we note that \(\beta < \alpha\) and \(\beta\) is closer to zero. Here, \(\beta\) can be interpreted as learning ability, i.e., the ability of a dog to learn from shock experiences. The increase in number of shocks barely raises the probability of non-avoidance (value of 𝜋𝑗) with little amount. Unless the trials & shocks increase considerably large in progression, it doesn’t mellow down well and mostly stays around 0.9.
However, it is not the case with \(\alpha\) which is more positive & farthest from ‘zero’. It imparts a significant decline in non-avoidance (𝜋𝑗) even for few instances where dog avoids the shock; therefore \(\alpha\) can be interpreted as retention ability i.e., the ability to retain the learning from previous shock experiences.
print(chain_samples_df_A["alpha"].describe(),"\n\n", chain_samples_df_A["beta"].describe())
count 3333.000000
mean 0.193567
std 0.011008
min 0.157281
25% 0.185966
50% 0.193318
75% 0.200985
max 0.236180
Name: alpha, dtype: float64
count 3333.000000
mean 0.007543
std 0.002389
min 0.001638
25% 0.005867
50% 0.007336
75% 0.008974
max 0.017314
Name: beta, dtype: float64
From the contour plot above following region in posterior distribution seems highly plausible for parameters:
For alpha,
0.18 < alpha < 0.20For beta
0.005 < beta < 0.009
Let us look at \(\frac{\alpha}{\beta}\) as a proxy to see which of the two (learning ability and retention ability) are domimant.
We are using \(\frac{\alpha}{\beta}\) as a probing device to answer that question, and similar quantities can be defined. With MCMC samples available, we can get posterior probabilties of any function of the model parameters (here \(\alpha, \beta\). Say, we can be interested in the \(E(\frac{\alpha}{\beta})\) or \(P(\frac{\alpha}{\beta}>1)\).
The latter quantity can be estimated by the Monte Carlo average as follows:
\(P(\frac{\alpha}{\beta}>1) = \frac{1}{n}\sum_{t=1}^{n} I(\alpha > \beta)\), i.e, the fraction of times \(\alpha > \beta\).
x1 = chain_samples_df_A["alpha"].to_numpy()
x2 = chain_samples_df_A["beta"].to_numpy()
p = np.mean(x1>x2)
print(p)
1.0
So, the posterior evidence for retention ability outweiging learning abilty is overwhelming. Had the model fit been right, this is the conclusion we would have drawn.
9. Commentary¶
Analyzing this dataset turned out be more complicated than we originally thought. Very little is known about the data or prior analysis techniques. The historical origins of WinBUGs reference, Stan, are not known. The original experiment from 1953 does not talk about this modeling at all.
pyrodocumentation is very poor. The parameterisations of the distribution has to be made very clear. There is no standard convention for defining the parameters of a distribution. For example, winBUGs, MATLAB, and Wikipedia can all define some distributions differently. If not checked carefully, one could be using variance in place of precision.
10. Exercises¶
Derive the expected value of Dogs getting shocked under the prior.
Derive the expected value of Dogs getting shocked under the posterior.
Verify the asymptotic analysis of the prior and posterior predictive responses.
Plot the posterior distribution, upto the normalization constant, for both models. What do you observe? Is the posterior multimodal?
Simulate the data under any model, and held it fixed (known or observed), with a particular learning rate and retention rate. Now fit the model to this data. What do you observe, Is the fit better?
Devevelop and implement an experiment to validate or invalidate the hypothesis that, under complete data, predicted posterior responses at an intermediate trial need not be sandwiched between data and prior.
Use
sigmoidlink function, instead ofexp. Complete the model specification, and carry out the inference.Instead of modeling the entire trials, consider the data at the last trial. Develop a model to analyze this aggregate data.
Develop a model where each Dog is allowed to have its own learning and retention parameters.
Develop a model with conjugate priors.
Current models in someways are performing auto-regression – the trials are indeed repeated measures. Can this data be analyzed as time-series? If yes, eloberate the techniques.
In the model construction, argue that the covariates are negatively correlated (learning rate and retention rate). Usually, this is not a good design. What are the alternatives?